
Nel nostro scorso articolo su Cloud Native abbiamo capito come questo termine indichi un approccio metodologico ed una serie di pratiche. Abbiamo anche individuato quali sono le necessità di business che hanno portato al suo sviluppo. Ora non ci resta che vedere come questi principi si traducono nella pratica.
Abbiamo parlato astrattamente di cambiamenti nei processi, nell’architettura, nelle infrastrutture e nella comunicazione. Quello che emerge nella pratica è la necessità di avere un ecosistema applicativo agile, disaccoppiato e modulare.

Da dove cominciare: 12-Factor design
Partiamo dal cuore di ogni applicazione: la codebase. Nel nostro scenario questa dovrà essere progettata per essere facilmente replicabile con tutte le sue dipendenze applicative e di sistema (containers + dev-prod parity), che ci sia una forte separazione tra il codice e le configurazioni (es: credenziali o parametri di connessione ad un database) e che sia stateless e share-nothing, ovvero che non si assuma che memoria e file-system siano persistenti tra le richieste, rendendola di fatto semplice da replicare.
Questi sono solo alcuni degli elementi che permettono di rendere la nostra applicazione Cloud Native, capace di sfruttare al meglio ambienti Cloud, e sono parte di una metodologia che prende il nome 12Factor, in riferimento a 12 principi generali: buone pratiche per sviluppare e progettare applicazioni moderne e/o per modernizzare quelle esistenti.
Gestione delle dipendenze
Per essere eseguita correttamente, ogni applicazione presenta una serie di dipendenze, sia applicative (es: language runtime, vendor libs) che di sistema (os-libs, versione del kernel, Linux o Windows).
Ad esempio, un’applicazione PHP per essere eseguita avrà sicuramente bisogno del PHP runtime ad una versione specifica (es: 5.6, 7.1, 7.2), che alcune estensioni siano presenti (es: mcrypt, mysql, redis) e che tutte le dipendenze applicative necessarie siano compilate ed installate correttamente (es: https://getcomposer.org). Lo stesso identico scenario è applicabile anche ad altri runtime come Java, Ruby, Python o Go.
Oggi è possibile risolvere questo problema in modo molto semplice grazie all’uso di Docker e dei Container, divenuti uno standard per poter isolare e pacchettizzare un’applicazione con tutte le sue dipendenze, rendendola dunque facilmente trasportabile ed eseguibile su ogni ambiente, sia di sviluppo che di produzione, nativo o cloud.
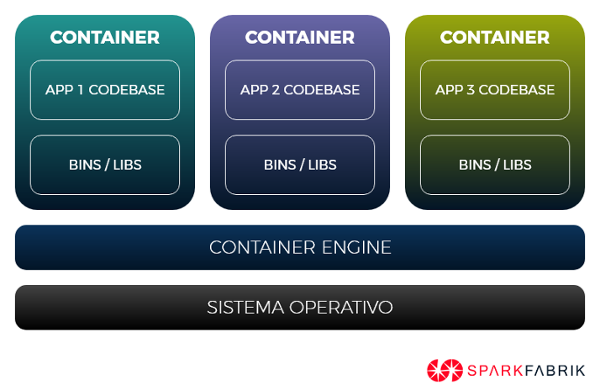
Configurazioni
Risolta la problematica della gestione delle dipendenze, ne rimane aperta un’altra: ogni ambiente può avere bisogno di una configurazione particolare, come ad esempio credenziali di accesso ad un servizio, connessione ad un database, un servizio di log oppure un storage persistente. Nelle applicazioni tradizionali queste informazioni vengono conservate in costanti all’interno del codice (hard coding), oppure in file statici di configurazione, riproponendoci la stessa situazione che abbiamo incontrato con le dipendenze system-wide: come rendere portabile e configurabile la nostra applicazione senza modificarne la codebase?
Uno dei principi chiave della metodologia 12-factor, e dunque delle applicazioni moderne, è quello di disaccoppiare la configurazione dalla parte applicativa. Ci sono diverse tecniche molto semplici, come l’uso di variabili d’ambiente (nativamente supportate da Docker), ovvero configurazioni a disposizione dell’applicazione ma iniettate a run-time dall’ambiente che la sta eseguendo, così da creare una netta separazione tra il codice e le configurazioni dei servizi, le quali non faranno più parte della codebase.
Stateless
In un architettura Cloud Native ogni processo è stateless, ovvero non assume che il suo comportamento possa dipendere da esecuzioni precedenti né che le componenti, come memoria e file-system, siano condivise e persistenti tra esecuzioni consecutive.
Dunque, come possiamo eseguire un workload tradizionale come un CMS — generalmente basato su concetto di filesystem e database persistenti — su un’architettura Cloud Native come Kubernetes?
Bene, la risposta è molto semplice, ed è quella di usare tecniche di modernizzazione per rendere il workload tradizionale adatto ad essere eseguito in ambienti cloud stateless moderni, senza dover per forza affrontare una riscrittura completa della codebase.
Ad esempio prendiamo il caso di un’applicazione tradizionale come Drupal, quindi uno stack basato su PHP + Nginx/Apache + Mysql. In questo scenario, un processo di modernizzazione dovrebbe focalizzarsi sui seguenti aspetti:
- Uso di un object storage (es: S3) per gli asset dinamici del CMS
- Streaming dei log dei servizi, invece che mantenerli su file-system (es: Stackdriver)
- Uso di un servizio nativo del cloud vendor per il database relazionale (es: CloudSQL, RDS)
Ogni workload tradizionale può essere modernizzato e portato in cloud senza affrontare un refactoring completo. Con le giuste modifiche è possibile rendere un’applicazione più semplice da scalare orizzontalmente, più resiliente agli errori e più performante, potendo sfruttare nativamente ogni servizio messo a disposizione del cloud vendor.
Questo approccio dunque, oltre a fornire l’immediato vantaggio di poter subito migrare i propri workload in cloud, permette di modernizzarne ogni aspetto anche in ottica di sviluppo a microservizi.
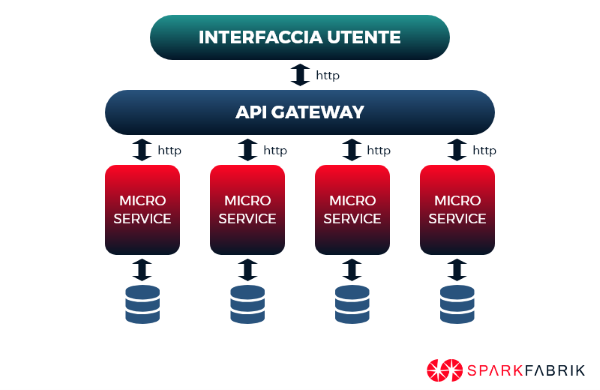
Processi
Che impatto ha questo modello di applicazione sull’organizzazione ed il flusso di lavoro? Quanto fin qui esposto aveva un chiaro obiettivo di business: reagire in tempi rapidi alle richieste mutevoli del mercato, con cicli di sviluppo e rilascio brevi e continui. Le condizioni per farlo le abbiamo ottenute, manca il come.
In uno scenario di sviluppo classico è molto facile trovare una netta separazione tra il team di sviluppo (devs) e il team di operations (ops). Questo era accettabile quando l’intervallo fra un deployment e l’altro poteva essere di giorni o settimane. Ma il nostro modello richiede rilasci rapidi e continui, idealmente ad intervalli di ore, ed una corrispondenza dello stack tecnologico nei vari deploy.
La soluzione è virare l’organizzazione verso una cultura DevOps, con team multidisciplinari e collaborativi, responsabili di un unico servizio ed in grado di seguirlo autonomamente dal suo sviluppo al suo deployment. Unitamente all’utilizzo di sistemi automatizzati per la Continuous Integration / Continuous Delivery (CI / CD), i team DevOps sono in grado di ridurre in cicli estremamente brevi sviluppo e messa in opera e, grazie all’isolamento e disaccoppiamento dei servizi su cui lavorano, sono idealmente indipendenti per quanto riguarda le scelte tecnologiche.
L’introduzione di CI/CD porta ad un’ulteriore modifica del workflow: la netta separazione in tre fasi del ciclo di vita della codebase. Distinguiamo in build, release e runtime queste tre fasi che verranno percorse a senso unico dalla nostra codebase:
BUILD: Rende eseguibile un determinato stato del repository (versione del codice). I codici binari vengono compilati, vengono inclusi gli asset appropriati e le dipendenze necessarie.
RELEASE: il codice ottenuto al termine della build viene in questa fase combinato con l’insieme di configurazioni specifiche per il deployment.
ESECUZIONE o RUNTIME: questa fase vede il codice in esecuzione nell’ambiente di destinazione finale.
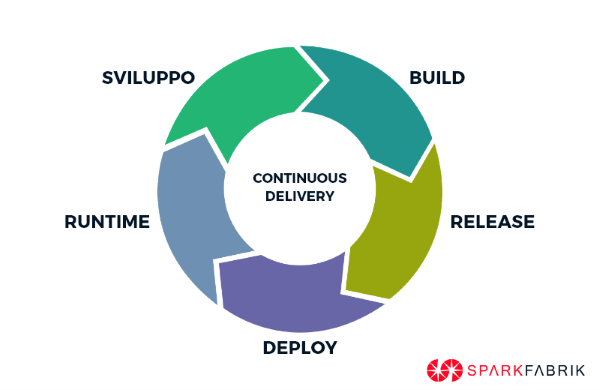
Questo processo è sempre implementato a senso unico così da garantirne l’automazione: quindi ogni modifica al codice deve prevedere un nuovo deployment con un ID specifico di rilascio.
L’insieme di ottimizzazioni e trasformazioni operative che abbiamo descritto, sono parte di una metodologia che ci permette di essere più efficienti, ottimizzare i costi operativi e ridurre il time-to-market.
Nei prossimi articoli vedremo con un esempio concreto il passaggio da un’applicazione monolitica ad una applicazione Cloud Native, applicando i principi della 12-Factor App methodology.
