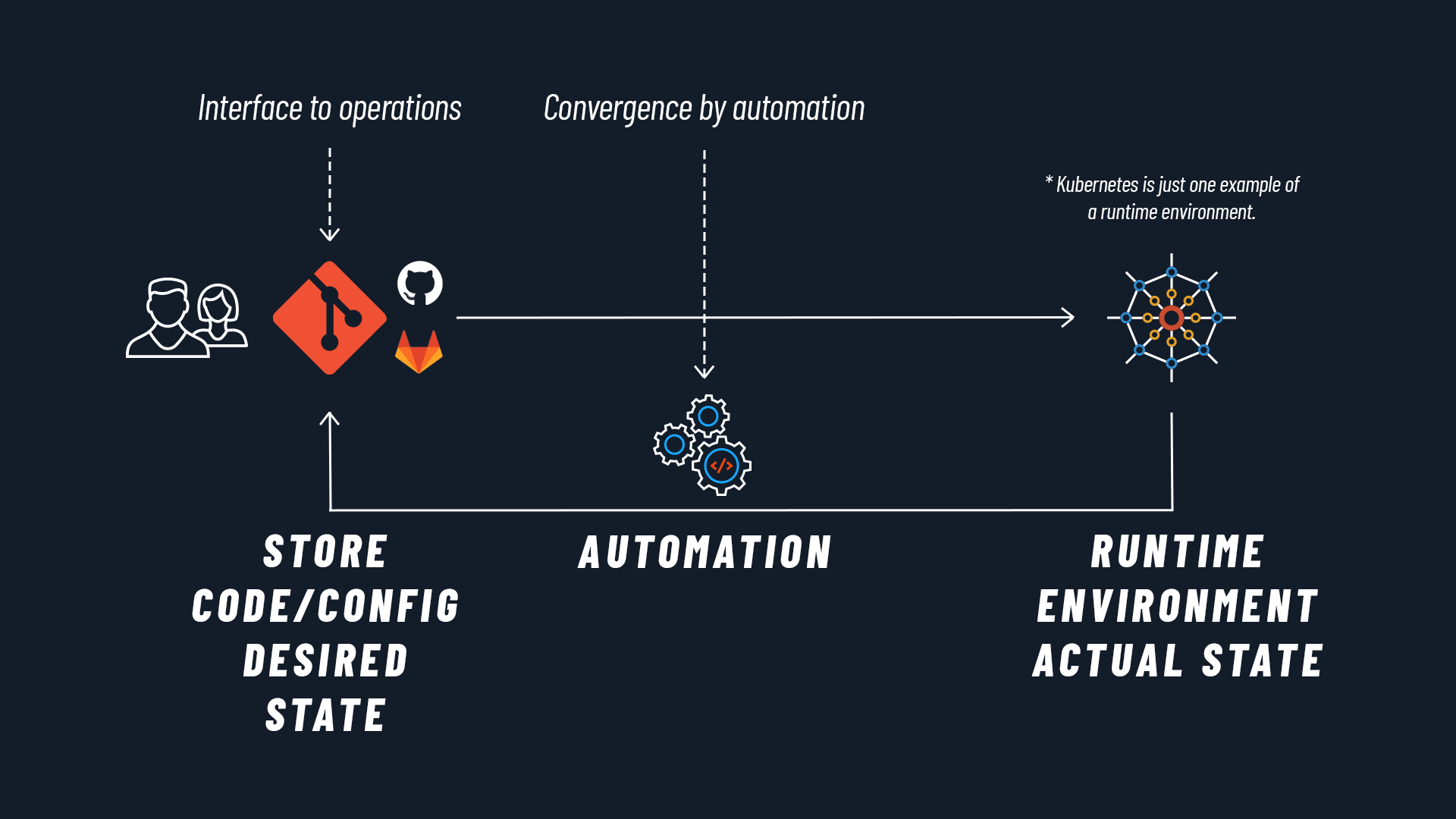
Il paradigma GitOps prevede l’uso di uno state store come storage per i manifest (o per il codice) dell’applicazione, state store che diventa così la singola fonte di verità. Quali benefici comporta questa pratica a livello organizzativo, di sicurezza e di prodotto?
Cos’è GitOps?
Nel nostro primo articolo su GitOps e Kubernetes, abbiamo definito GitOps come “un paradigma volto ad implementare Continuous Deployment e/o Continuous Delivery per applicazioni Cloud Native.”
Questa frase riassume il concetto di GitOps, su cui tuttavia non esiste ancora una definizione universalmente riconosciuta dalla community, complice la sua “giovane età” (l’espressione è stata usata per la prima volta nel 2017). O meglio, ne esiste una proposta ancora grezza, non adottata in toto.
Ciò che è ormai da tutti comprovato sono i benefici che questo paradigma comporta: in primis maggiori osservabilità, sicurezza e produttività.
Il nome stesso di GitOps ci aiuta a definirne il contesto:
- Git: è sistema di controllo versione più diffuso al mondo, ormai standard de facto. Nel paradigma GitOps, Git rappresenta la singola fonte di verità per lo stato del nostro sistema. È infatti nel repository Git che viene versionato lo stato desiderato del sistema.
- Ops: le operazioni di deployment vengono integrate in Git. Non occorre cambiare strumento per distribuire l’applicazione, tutto accade nel sistema di controllo della versione utilizzato per sviluppare l'applicazione.

Come funziona GitOps?
Nonostante la progressiva automazione dei processi nel ciclo di vita del rilascio del software, l'infrastruttura richiede ancora molto lavoro manuale. GitOps si inserisce in questo contesto, consentendo una maggiore velocità di distribuzione, scalabilità ed elasticità infrastrutturale.
In sostanza, GitOps viene utilizzato per automatizzare il processo di provisioning dell’infrastruttura e aiutare i team di sviluppo a gestire efficacemente le risorse cloud necessarie a modalità di rilascio continue.
I team che adottano GitOps utilizzano i file di configurazione archiviati come codice (Infrastructure as Code). Per questo, in un certo senso, GitOps è un'evoluzione di Infrastructure as Code che utilizza i repository Git come singola fonte di attendibilità. Git diviene così l’unico riferimento per la creazione e l'aggiornamento è l'unico meccanismo di controllo.
LEGGI ANCHE: GitOps e Kubernetes: CI/CD per applicazioni Cloud Native
GitOps vs DevOps: le differenze
L’assonanza con il termine “DevOps” salta subito all’orecchio. Che relazione intercorre quindi tra GitOps e DevOps?
DevOps (e le sue evoluzioni come DevSecOps) sono modelli che promuovono la collaborazione tra aree precedentemente separate. Si basano sul principio di avvicinare team diversi (come quelli di operations e sviluppo) per ottimizzare i loro flussi di lavoro.
Questo stesso approccio vale anche per GitOps, che tuttavia si concentra interamente su Git. Possiamo quindi considerare GitOps come una best practice DevOps. Per questo, DevOps e GitOps sono perfettamente combinabili.
GitOps viene anche descritto come un modo di fare DevOps più orientato al Cloud Native, che sfrutta la possibilità di descrivere tutto a livello di codice e gli automatismi per astrarre il team di Operations da compiti a basso valore aggiunto delegabili alle macchine. Al contempo, permette al team Development di eseguire modifiche al codice e mandarle in produzione in autonomia, senza dipendere dall’intervento del team Operations.
Facciamo inoltre una doverosa premessa: sebbene GitOps sia un insieme di buone pratiche applicabili indipendentemente dalla tecnologia sottostante, ad oggi viene usato principalmente nel contesto di Kubernetes. Kubernetes non ha bisogno di presentazioni, essendo la piattaforma open source per la gestione di carichi di lavoro e servizi containerizzati più adottata.
Breve storia di GitOps
Il termine GitOps è comparso per la prima volta nel 2017 su un celebre blog post scritto da Alexis Richardson, co-founder e CEO di Weaveworks: “GitOps: Operations by Pull Request”.
L’interesse verso questa metodologia è cresciuto rapidamente, sia da parte degli utenti che hanno iniziato ad implementarla, sia da parte delle aziende che hanno ampliato la loro offerta con servizi GitOps-based.
Un’ulteriore conferma è arrivata dal CNCF End User Technology Radar di giugno 2020, che ha eletto Flux (uno degli strumenti GitOps per eccellenza) a tecnologia da adottare per la Continuous Delivery nel contesto Kubernetes. Ormai era chiaro: GitOps stava rapidamente diventando la metodologia preferita per il funzionamento delle moderne infrastrutture e applicazioni Cloud Native.
È su queste premesse che, a novembre 2020, è nato nell’ambito della CNCF il GitOps Working Group, il cui scopo è aprire la strada verso la definizione di uno standard GitOps neutrale rispetto ai vari vendor.
Non perderti il Nostro Tech Talk a tema GitOps! Andrea Panisson ci parla dello stato dell’arte di questo paradigma:
I principi di GitOps
I principi alla base di GitOps contribuiscono alla definizione del modello indipendentemente dalla sua implementazione, e difatti non citano né Git né Kubernetes. Sono:
- Il principio della configurazione dichiarativa
- Il principio della immutabilità delle versioni della configurazione
- Il principio della riconciliazione continua dello stato
- Il principio delle operazioni attraverso la dichiarazione
1. Il principio della configurazione dichiarativa
Il primo principio ci dice che un sistema gestito da GitOps deve avere il suo stato desiderato espresso in modo dichiarativo sotto forma di dati, in un formato che sia scrivibile e leggibile sia dagli umani che dalle macchine.
Lo stato desiderato di un sistema è definito come l’insieme di dati sufficienti per ricreare il sistema partendo da zero, in modo che le diverse istanze siano indistinguibili dal punto di vista comportamentale l’una dall’altra.
La natura dichiarativa di Kubernetes è quindi la base perfetta per il modello GitOps.
2. Il principio della immutabilità delle versioni della configurazione
Lo stato desiderato deve essere memorizzato in un modo che supporti il versionamento, l'immutabilità delle versioni e mantenga una storia completa delle versioni.
Chiamiamo i sistemi che memorizzano lo stato desiderato in questo modo “State Stores”. Per riprendere la definizione fornita dalla community, lo state store è “un sistema per l'archiviazione di Stati desiderati versionati e immutabili, che fornisce controllo degli accessi e auditing sulle modifiche allo Stato desiderato”.
Nel nostro caso ci riferiamo chiaramente al repository Git.
3. Il principio della riconciliazione continua dello stato
Con riconciliazione intendiamo un processo nel quale lo stato corrente del sistema viene continuamente confrontato e reso coerente con lo stato desiderato che troviamo definito nello State Store.
Concretamente, degli agenti software confrontano continuamente e automaticamente lo stato attuale del sistema con il suo stato desiderato. Se lo stato attuale e quello desiderato differiscono, vengono immediatamente tentate azioni automatiche per riportare lo stato attuale allo stato desiderato. In caso non abbiano successo, viene notificato il team che può intervenire prontamente, limitando quindi il tempo di malfunzionamento.
Nel contesto Kubernetes, questi agenti software sono dei kubernetes controller (o Kubernetes operator) e quelli che oggi come oggi dominano la scena sono indubbiamente due: Flux CD e Argo CD. Entrambi progetti maturi supportati dalla CNCF e da una vasta community, hanno funzionalità molto simili.
4. Il principio delle operazioni attraverso la dichiarazione
Né gli sviluppatori né un agente software esterno possono interagire direttamente con il sistema. Il meccanismo attraverso il quale è possibile applicare un cambiamento al sistema, infatti, è attraverso la creazione di una nuova versione dichiarativa dello stato desiderato all’interno dello State Store.
E questo è un punto fondamentale, perché significa che l’unico modo che abbiamo per fare delle modifiche è tramite un commit su di un repository Git.
Git diventa la singola fonte di verità per lo stato del sistema, nonché l’unico luogo in cui operiamo. Ecco perché parliamo di esperienza incentrata sullo sviluppatore: tutto avviene all’interno di uno strumento con cui i Dev lavorano abitualmente.
Perché usare GitOps?
Possiamo identificare 4 grandi benefici derivanti dall’uso di queste pratiche:
- Osservabilità: per vedere cosa c’è deployato nel cluster Kubernetes basta andare a navigare il repository dell’environment, con la certezza che esso rappresenta la singola fonte di verità. Fondamentali sono il già citato processo di riconciliazione, che lavora continuamente per riportare il sistema allo stato desiderato, e il sistema di alert automatici in caso il tentativo di riconciliazione fallisca.
- Sicurezza: è possibile ridurre i problemi di sicurezza derivanti dall’esposizione delle API di Kubernetes alla Continuous Integration. Si tratta di un grande pro per tutte le aziende che vogliono dare accesso all’ambiente di produzione solo a una o poche persone del team Operations. Questo tipo di organizzazione rende complesso apportare modifiche urgenti in caso di assenza delle persone responsabili, ma grazie a GitOps le modifiche vengono fatte sul repository, eliminando di fatto il problema degli accessi all’ambiente.
- Disaster recovery: abbiamo detto che lo sviluppatore è autonomo nell’apportare modifiche. Questo ovviamente vale anche per i casi di particolare urgenza in cui le modifiche apportate abbiamo provocato degli errori: usando Git è possibile eseguire il rollback alla versione precedente dell’applicativo in modo relativamente semplice e rapido.
- Produttività: possiamo considerare quest’ultimo punto come una conseguenza di tutti gli altri. È chiaro come adottare le prassi GitOps porti a flussi di lavoro più snelli e a una migliore collaborazione tra i team di sviluppo e di operations, semplificando la risoluzione dei problemi ed eliminando i task automatizzabili. Un’evidenza concreta dell’aumento della produttività è data dal numero di deploy, potenzialmente illimitati e svolti in autonomia dallo sviluppatore.
Come implementare GitOps?
Non esiste una risposta univoca a questa domanda, poiché il modo migliore per i team di implementare GitOps dipende da esigenze e obiettivi specifici.
Tuttavia, è possibile iniziare con GitOps seguendo alcune best practice, ad esempio:
- Utilizzando un repository GitOps dedicato per tutti i membri del team per condividere configurazioni e codice;
- sfruttare l'automazione nella distribuzione delle modifiche al codice;
- usare l'impostazione di avvisi per notificare al team quando si verificano modifiche.
Più concretamente, GitOps richiede tre componenti principali, che in parte abbiamo già citato. Comprendere ed utilizzare questi tre elementi è fondamentale per implementare GitOps.
IaC
Infrastructure as Code (IaC) è stato un grande passo avanti per la gestione della configurazione, in quanto ha consentito di definire l'intero hardware come codice, accelerando così il provisioning dell'infrastruttura e migliorando l'utilizzo delle risorse. Adottando Git come sistema di controllo della versione prevalente, GitOps è emerso come l'ultimo passo avanti nell'evoluzione della gestione della configurazione del cloud.
MRs
Le richieste di unione - merge request (MR) - sono il metodo di modifica utilizzato da GitOps per qualsiasi aggiornamento dell'infrastruttura. Attraverso le MR i team possono lavorare insieme con revisioni e commenti, ricevere le approvazioni ufficiali e avere un registro di controllo.
CI/CD
Per comprendere il panorama GitOps è bene anche avere presente il funzionamento di una pipeline CI/CD. Per approfondire questo aspetto ti consigliamo il nostro articolo su Continuous Integration, Continuous Delivery e Continuous Deployment.
GitOps è la metodologia giusta per la tua azienda?
Ricollegandoci all’ultimo vantaggi esposto, quello della produttività, possiamo affermare con certezza che GitOps rappresenta un vantaggio innegabile a livello di business. Il semplice fatto di non dover più aspettare del tempo per mandare live delle modifiche, potendole totalmente automatizzare in modalità Cloud Native, implica la possibilità di offrire agli utenti servizi digitali sempre aggiornati, assecondando le esigenze del business in tempi brevi.
Ma come in tutto, anche GitOps presenta degli aspetti che per alcune aziende possono rappresentare una sfida.
Innanzitutto, è best practice la creazione di due repository: quello che contiene il codice dell’applicazione e quello che contiene i codici (i manifest nel contesto Kubernetes) che descrivono l’infrastruttura.
Le aziende che hanno già un elevato numero di repository perché gestiscono molte applicazioni o perché hanno repository diversi per ogni microservizio, potrebbero incorrere in un aumento di complessità non indifferente. D’altro canto però, su progetti di tali dimensioni, una metodologia come GitOps diventa una vera e propria necessità. Nella generalità dei casi, vale quindi la pena affrontare l’aumento di complessità in cambio dei numerosi vantaggi che si possono ottenere.
L’implementazione di GitOps richiede chiaramente del lavoro, quindi è bene fare dei ragionamenti in termini di costi benefici. Ad esempio, aziende con un consolidato approccio DevOps potrebbero essere in grado di fare deploy veloci tutti i giorni anche senza GitOps. In questi casi i benefici ottenibili potrebbero sembrare minori, ma di contro va detto che anche il tempo di implementazione si riduce drasticamente.
Anche nel caso di applicazioni o siti di ridotte dimensioni e funzionalità, si pone il dubbio: ha senso adottare GitOps? Non esiste una risposta universale. Quello che è certo è che i vantaggi del paradigma non vengono meno: in definitiva dipende dalla fiducia che si accorda al modello e all’importanza dei benefici apportati rispetto al business.
Un altro punto da considerare riguarda le policy di sviluppo aziendali. Per alcune realtà, ad esempio, è impensabile tagliare dal processo la fase di auditing del codice. Di norma con GitOps questa fase è automatizzata e non richiede il controllo dell’operatore: ciò significa che non è possibile fare GitOps? Non necessariamente, il modello è flessibile e può essere adattato alle esigenze aziendali. Ad esempio è possibile fare l’audit su un branch diverso da quello in cui l’operatore è in ascolto, oppure su un altro repository da approvare e sincronizzare dopo il controllo.
Per concludere, è consigliabile implementare GitOps?
In fin dei conti, Gitops non è di per sé qualcosa di nuovo. Possiamo considerarlo come la modalità naturale di fare operations e DevOps all’interno del contesto Cloud Native e di Kubernetes. In altre parole, si tratta di un nuovo modo di chiamare alcuni principi e buone pratiche che esistevano già molto prima che il termine fosse inventato.
Ciò che GitOps aggiunge a queste best practice è un vero e proprio metodo che, come abbiamo visto, la community sta contribuendo a far crescere e consolidare negli anni. Ad oggi ci sono molti punti aperti, domande senza risposta e modelli da strutturare, su cui possiamo aspettarci dei contributi da parte del GitOps Working Group.
Anche senza che ogni aspetto sia chiaramente definito, il paradigma e le relative tecnologie sono a un livello di maturità tale da poter essere adottati senza rischi dalle aziende. Per rispondere alla domanda con cui abbiamo aperto questo paragrafo conclusivo, GitOps è un modello che permette di fare un passo in più, dai benefici misurabili e sicuramente consigliato alla maggior parte delle aziende che già si muovono nel contesto Cloud Native.
