Grazie all'architettura serverless gli sviluppatori possono focalizzarsi sulla creazione di codice anziché sulla gestione del server. Come funziona questo approccio sempre più diffuso?
Cos’è il serverless computing?
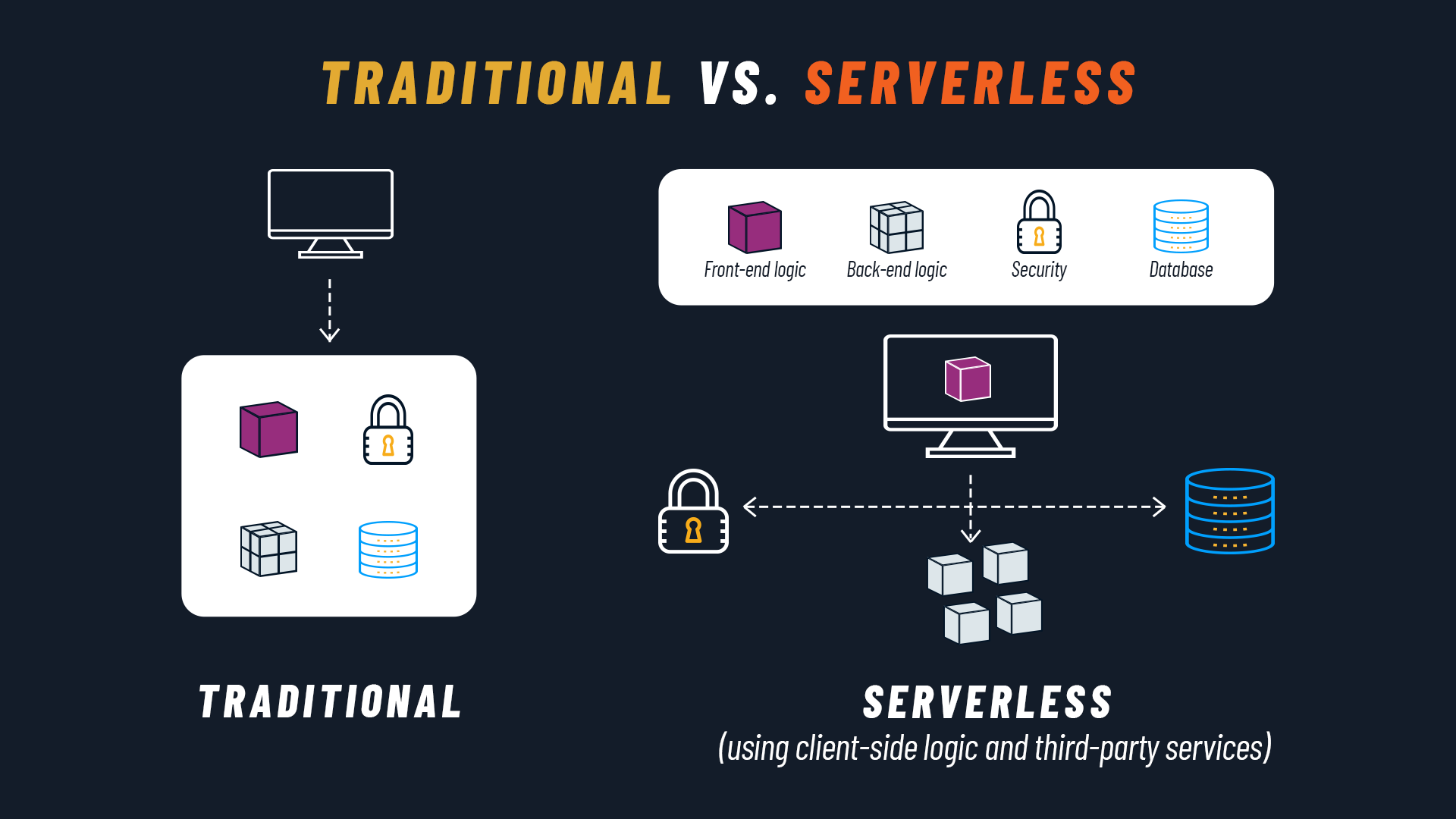
Partiamo dalla domanda più ovvia: che cos’è il serverless computing? Possiamo definirlo come un modello di sviluppo Cloud Native in cui il Cloud provider gestisce l’infrastruttura, allocando in modo dinamico solo le risorse di elaborazione e di archiviazione necessarie per eseguire una particolare porzione di codice.
Dal momento che tale processo è eseguito dal cloud provider, gli sviluppatori possono concentrarsi sul software senza preoccuparsi dell'infrastruttura. Agli sviluppatori è richiesto solamente di creare e deployare il codice della funzione o applicazione da eseguire, oppure un container con il codice e la descrizione delle dipendenze.
Il successo del paradigma serverless è legato anche ai vantaggi che garantisce alle aziende, come scalabilità e ottimizzazione dei costi. Il modello di esecuzione serverless è infatti basato su eventi, di conseguenza si pagano le funzioni serverless solo quando vengono chiamate (pay-as-you-go), con la possibilità di scalare automaticamente verso l’alto o verso il basso (arrivando anche a zero, in assenza di richieste).

Serverless computing: da quali esigenze nasce
Prima di scendere nei dettagli è bene fare una specifica importante. La parola “serverless” può trarre in inganno, inducendoci a credere che il server fisico non sia presente. Chiaramente non è così: ciò che è serverless, piuttosto, è l’esperienza dello sviluppatore.
In un contesto serverless, infatti, lo sviluppatore non deve preoccuparsi della configurazione, manutenzione e scalabilità del server. Può quindi concentrarsi sull’attività che genera maggior valore, ovvero la creazione del codice dell'applicazione, mentre sarà il fornitore a gestire tutti gli aspetti legati all’infrastruttura.
La domanda sorge spontanea: non è sempre stato così? In fondo, il programmatore si occupa di scrivere codice, e il sistemista di farlo girare sul server. In realtà non è così banale. In un’applicazione di tipo enterprise non può esserci totale mancanza di dialogo tra le due parti: non sarebbe possibile far funzionare alcun progetto web se lo sviluppatore scrivesse un’applicazione per un server che non la può far girare.
Ecco perché l’esigenza percepita storicamente dai programmatori era di potersi focalizzare sulla scrittura di codice senza preoccuparsi di se e come questo girasse nel server. La risposta è arrivata nel tempo da diversi fronti: dalle macchine virtuali, dal cloud computing, dai container e, più recentemente, dal paradigma serverless.
Infine va citata anche una chiara esigenza economica delle aziende: quella di non pagare il server per i periodi in cui non sta effettivamente servendo alcuna richiesta. A questa necessità il modello serverless risponde con una politica di pay-as-you-go, come abbiamo già accennato.
Due tipologie di servizi serverless
FaaS (Function-as-a-Service)
Il paradigma serverless si è concretizzato inizialmente come Function-as-a-Service (FaaS), un servizio che permette di eseguire e gestire il codice delle applicazioni come singole funzioni che sono chiamate attraverso eventi o richieste HTTP.
Possiamo immaginare la funzione come la parte più piccola dell’applicazione (e viceversa quest’ultima come il bundle di più funzioni). In alcuni casi l’applicazione può essere costituita da un’unica funzione: pensiamo, ad esempio, a un chatbot che, ricevendo una domanda, genera una precisa risposta. La funzione viene eseguita solo in risposta ad un evento, come può essere il click di un utente sul chatbot.
Con FaaS gli sviluppatori possono costruire un'architettura modulare, creando una base di codice più scalabile senza dover spendere risorse per mantenere il server sottostante.
Ogni Cloud vendor ha la propria proposta serverless, tra cui le più importanti sono AWS Lambda di Amazon, Cloud Functions di Google e Azure Functions di Microsoft. Esse permettono di caricare semplicemente il codice insieme alle eventuali dipendenze e distribuirlo automaticamente in un container. A quel punto la funzione è disponibile, e sarà eseguita quando richiesto, secondo gli eventi configurati.
Oggi siamo a uno step successivo: solitamente quando si parla di serverless ci si riferisce al modello SaaS (Software-as-a-Service) per intendere un’applicazione che è interamente serverless. In questo caso non abbiamo più una sola funzione, ma un insieme di funzioni, servizi e dipendenze.
BaaS (Backend-as-a-Service)
Oltre a FaaS, un'altra categoria di prodotti di serverless computing molto citata è rappresentata dal Backend-as-a-Service.
Questo modello permette agli sviluppatori di accedere a diversi servizi di terze parti. I Cloud provider forniscono, ad esempio, servizi per l'autenticazione degli utenti, la gestione del database, l'aggiornamento remoto, le notifiche push per le app mobile, l'archiviazione nel cloud e l'hosting.
Le funzioni serverless sono chiamate tramite API, per cui gli sviluppatori sono in grado di integrare tutte le funzionalità di backend di cui hanno bisogno, senza dover costruire l’intera infrastruttura backend.
I serverless provider più scelti
Secondo il Survey Report 2020 della CNCF (Cloud Native Computing Foundation), il 60% delle aziende partecipanti che usano serverless sceglie le piattaforme dei i principali provider di cloud pubblico sul mercato: AWS Lambda (57%), Google Cloud Functions (27%) e Azure Functions (24%).
Il 13% opta invece per soluzioni serverless installabili, tra cui le più adottate sono Knative (27%), OpenFaaS (10%) e Kubeless (5%).
Infine, per chi vuole mantenere l’infrastruttura on-prem e creare funzioni o applicazioni serverless c’è un’ulteriore opzione costituita da OpenShift, software open source gestito da RedHat. OpenShift può essere installato sulle macchine in locale e permette di sfruttare i vantaggi di serverless anche a quelle realtà che, magari per questioni legislative, non hanno la possibilità di condividere certi tipi di dati con fornitori cloud esterni.
Cos’è Knative? Kubernetes Serverless
La piattaforma di orchestrazione dei container Kubernetes è spesso utilizzata per l'esecuzione degli ambienti serverless, ma non è nativamente predisposta per questa funzionalità. Per risolvere questa limitazione, è stato sviluppato Knative, un progetto open source che aggiunge componenti per il deployment, l'esecuzione e la gestione di applicazioni serverless su Kubernetes.
Con Knative, è possibile eseguire il deployment del codice come immagine container e il sistema lo avvia solo quando necessario. Knative è composto da tre componenti principali: Build, Serving e Eventing, che consentono la creazione dei container, il deployment rapido e la scalabilità automatica, nonché l'utilizzo e la generazione di eventi per attivare le applicazioni.
A differenza dei framework serverless precedenti, Knative è progettato per il deployment di qualsiasi tipo di carico di lavoro applicativo, dai monoliti ai microservizi e alle microfunzioni. Inoltre, Knative può essere eseguito su qualsiasi piattaforma cloud che supporta Kubernetes, inclusi i data center on premise, offrendo alle aziende maggiore agilità e flessibilità nella gestione dei carichi di lavoro serverless.
Vantaggi e svantaggi delle architetture serverless
Arrivati fin qui, sono probabilmente già chiari i principali benefici di serverless. Ricapitoliamoli passando in rassegna le principali promesse di questo paradigma:
- Nessuna gestione dei server e focus sullo sviluppo del prodotto: il perimetro di release e deployment è più circoscritto, riducendo la complessità, aumentando (potenzialmente) la frequenza dei rilasci e il time-to-market
- Scaling automatico in base all’uso
- (High) availability e tolleranza degli errori incluse
- Minori costi fissi: si paga per valore e servizi effettivamente utilizzati, non si ha nessun addebito per il tempo di non utilizzo
Come tutte le soluzioni, anche serverless ha degli aspetti negativi, come il possibile vendor lock-in, la difficoltà di previsione dei costi e i cold start. Tutti svantaggi che, nella maggior parte dei casi, non superano i vantaggi ottenibili.
Se vuoi approfondire il tema ti suggeriamo il nostro articolo sui pro e contro delle architetture serverless.
Serverless e Cloud Native
Parlando di serverless il riferimento al Cloud Native è d'obbligo. D’altronde in apertura abbiamo definito serverless proprio come un modello di sviluppo Cloud Native. In che modo sono legati questi due concetti?
Alla base del paradigma Cloud Native c’è la 12 Factor Methodology: 12 principi che guidano lo sviluppo in ottica Cloud Native. Essi possono essere tradotti concretamente proprio grazie alla funzione serverless, che li rispecchia (e li rispetta) appieno. Per citare alcuni punti di contatto, la funzione serverless descrive l’infrastruttura, è riproducibile, è scalabile, ed è deployabile in isolamento.
Consigliamo questo blog post di AWS per approfondire come serverless interpreta ciascuno dei 12 principi.
Serverless e microservizi: quali sono le differenze?
Microservizi e serverless sono due concetti importanti nel Cloud Native. Sebbene siano spesso correlati, svolgono ruoli diversi negli ambienti software moderni.
I microservizi sono un modello architetturale in cui le applicazioni vengono suddivise in piccoli servizi indipendenti. Questo contrasta con le applicazioni monolitiche, in cui tutte le funzionalità sono raggruppate insieme.
D'altra parte, l’approccio serverless consente agli sviluppatori di non preoccuparsi della gestione del server e di concentrarsi sulla creazione del codice dell'applicazione. Nel modello serverless, il codice viene eseguito solo su richiesta, in risposta a trigger configurati dagli sviluppatori.
Sebbene siano tecnologie diverse, microservizi e serverless sono strettamente correlate. Le funzioni serverless possono essere utilizzate per ospitare i microservizi, creando così un "microservizio serverless".
È importante notare che non tutti i microservizi vengono eseguiti come funzioni serverless, poiché alcuni richiedono un'esecuzione continua. Inoltre, non è necessario utilizzare un'architettura a microservizi per beneficiare del serverless, anche se è raro che un'applicazione monolitica tragga vantaggio dall'essere distribuita su una piattaforma serverless.
Un'altra differenza è che gli ambienti serverless possono includere diverse funzioni condivise da più applicazioni, mentre i microservizi sono più specifici di un'applicazione e meno comuni da condividere tra più applicazioni.
In conclusione, serverless e microservizi sono due tecnologie complementari nel mondo del cloud computing nativo, che offrono approcci diversi per la progettazione e l'esecuzione delle applicazioni. La scelta tra queste due opzioni dipende dalle esigenze specifiche del progetto e dalla scalabilità, ma entrambe offrono vantaggi significativi per lo sviluppo di applicazioni moderne e flessibili.
Serverless case studies
Le aziende che hanno scelto il paradigma serverless si sono moltiplicate negli ultimi anni.
La crescita è rilevata anche dalla CNCF nel suo Survey Report 2020:
- Il 30% dei partecipanti alla ricerca usa il serverless computing
- Il 12% sostiene di star valutando le soluzioni serverless
- Il 14% ha intenzione di implementarlo nei prossimi 12 mesi
Tra i case studies più conosciuti e rilevanti non possiamo non citare Netflix, che già nel 2014 ha iniziato a usare AWS Lambda per sostituire processi inefficienti, ridurre gli errori e ottimizzare i tempi.
Diversi sono gli esempi nel settore editoriale, come il Seattle Times, il Guardian, PhotoVogue e ilGiornale.it.
Un caso recente e interessante è quello di Coca-Cola, che ha scelto serverless per implementare Coca-Cola Freestyle, un servizio che consente di avviare l’erogazione della bibita attraverso lo smartphone. Serverless assicura agli utenti una bassa latenza e quindi un’ottima user experience.
I casi studio non si fermano certo qui, anzi coinvolgono realtà di ogni tipo e settore distribuite in tutto il mondo. Dagli ecommerce ai giornali online, dai siti istituzionali ai servizi di streaming: le architettura serverless sono già state messe alla prova nei più disparati campi applicativi con ottimi risultati.
Qual è il futuro del serverless computing?
L'adozione del serverless computing sta crescendo rapidamente, spinta dalla necessità di ridurre i costi e aumentare l'agilità. Secondo un rapporto di MarketsandMarkets, il mercato dell'architettura serverless dovrebbe triplicare, passando da 3,3 miliardi di dollari nel 2020 a 14,1 miliardi di dollari entro il 2025.
- Un mercato sempre più variegato: Oltre ai giganti del settore come Amazon AWS, Microsoft Azure e Google GCP, sempre più provider emergenti entreranno nel mercato del serverless.
- Maggiore sicurezza: La sicurezza è un fattore di grande importanza, poiché molti progetti serverless open source presentano vulnerabilità critiche. Sarà quindi necessario un impegno maggiore da parte dei clienti e degli sviluppatori per garantire un ambiente serverless sicuro. Gli sviluppatori dovranno rivalutare i protocolli DevSecOps, concentrandosi sull'integrità dei dati, la sicurezza e la privacy, per affrontare questa evoluzione.
- Visibilità e monitoraggio: Un'altra sfida per gli sviluppatori riguarda l'osservazione e il monitoraggio delle applicazioni serverless. Gli strumenti di osservazione e monitoraggio miglioreranno per consentire una gestione più efficace delle applicazioni serverless.
- Più attenzione ai vantaggi ambientali: Oltre ai vantaggi finanziari, il serverless offre anche vantaggi ambientali grazie alla riduzione del consumo energetico. L'adozione di framework come Green Cloud Computing, FinOpS e GreenOps favorirà ulteriormente la crescita del serverless.
- Piattaforme interconnesse: Un'altra tendenza emergente è l'interconnessione delle piattaforme serverless per il cloud, l'edge e l'ambiente on-premise. Questo consentirà un deployment flessibile e scalabile delle applicazioni serverless in diversi ambienti, favorendo l'Internet of Things (IoT), l'analisi dei big data e il machine learning. Inoltre, ci saranno nuove opportunità per la creazione di mercati di sistemi software complessi pronti all'uso.
In conclusione, il futuro del computing serverless offre molte opportunità, ma richiederà un impegno costante per garantire la sicurezza, l'efficienza e l'interconnessione delle applicazioni serverless in diversi ambienti.
